Information Storage, Processing, and Transfer
The central dogma of molecular biology is that information is transferred from DNA to RNA to proteins. The proteins (which include the enzymes and structural components of cells) are directly responsible for most cellular activities and functions. The information needed for all functions of all organisms is stored in the genomic DNA sequence, which contains discrete units defined as genes. Each gene encodes a protein whose function and activity are determined by its primary sequence. The discovery of colinearity of theDNAnucleotide sequence and the amino acid sequence of the encoded polypeptide in prokaryotes and their viruses led to the discovery of the genetic code which postulates that a three-nucleotide sequence in DNA, called a codon, is responsible for insertion of a specific amino acid in the polypeptide chain during its synthesis.Thus, the information content in the genomic DNA of a cell needs not only to be preserved and passed on to the progeny cells during replication, an essential characteristic and requirement of all living organisms, but also has to be processed and transferred via proteins to the ultimate cellular activities, including the metabolism.
Elucidation of the double-helical structure of DNA lends itself to an elegant but simple mechanism of perpetuation of the DNA information during duplication, called semi-conservative replication. In this model (Fig. 2), the two strands of DNA separate, and each then acts as the template for synthesis of a new daughter strand based on base pair complementarity and strand polarity. Thus, the two strands of the DNA double helix, though not identical in sequence, are equivalent in information content.
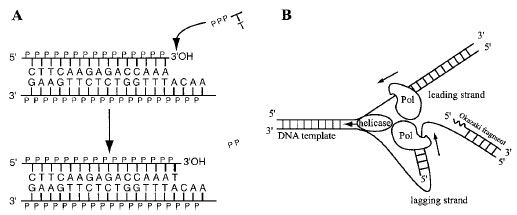 |
| FIGURE 2 DNA polymerization reaction. (A) According to the base pairing rules, a deoxythymidinetriphosphate (dTTP) is added at the 3´-OH end of the top strand through a transesterification reaction catalyzed by a DNA polymerase. (B) Two units of DNA polymerase form a heterodimer complex to carry out replication in a semi-conservative way. Because the reaction goes only in the 5´→3´ direction, one side (the leading strand) is synthesized continuously, while the other (the lagging strand) consists of short DNA fragments (Okazaki fragment). DNA replication is initiated by an RNA primer (waved line) which is synthesized by a primase. There are a number of accessory but essential proteins besides the polymerase unit. |
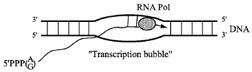 |
| FIGURE 3 An RNA polymerase unit (filled circle), which consists of multiple factors, opens DNA helix (shown as a bubble) and synthesizes RNA in the 5´→3´ direction. |
The mRNA is read out by ribosomes, the ribonucleoprotein complex which functions as the factory for protein synthesis. The codons are recognized as blocks because they code for specific amino acids. Thus, the linear polypeptide sequence is determined by the linear mRNA sequence.
Support our developers




